
- Hyperscalers will spend roughly $700B on AI infrastructure in 2026 across AMZN, GOOGL, META, MSFT and ORCL — every one of them now ships its own custom AI silicon in production, not just on a roadmap.
- The non-obvious investor edge is not picking the NVDA-vs-ASIC fight; it is owning the ASIC-stack picks-and-shovels — AVGO, MRVL, TSMC, SNPS, CDNS — which get paid in every scenario.
- Anthropic is simultaneously committed to up to 1 million Google Ironwood TPUs AND $100B+ in AWS Trainium spend over the next decade. The largest AI customer in the world is multi-vendor on principle.
The custom silicon race has quietly become the most important structural story in AI infrastructure, and the size of the prize is bigger than most retail investors realise. Hyperscalers are guiding to roughly $700 billion in capex in 2026: Amazon at $200B, Alphabet at $175–185B, Meta at $115–135B, Microsoft tracking $120B+, and Oracle adding $50B. NVIDIA still captures the majority of the AI-silicon line in those budgets — but every one of those buyers now ships its own AI accelerator in production. This is not a tabletop threat anymore. It is the largest in-house chip program in computing history, running concurrent across four companies.
NVIDIA — ticker NVDA — last traded at $220.78 going into publication on May 20, 2026, and that print is the right lens for the rest of this piece. The bull case for NVDA over the next two years is not whether hyperscalers buy fewer GPUs; it is whether total AI demand outruns hyperscaler ASIC capacity. The bear case is the inverse. The actual answer — and the investor edge — sits one layer above the NVDA-vs-ASIC fight, in the supply chain that gets paid either way.
Why the custom silicon race matters now
Four forces converged in the last 18 months to make in-house AI silicon a board-level priority at every hyperscaler:
TCO arithmetic. NVIDIA gross margin structurally runs in the 71–75% range — Q4 FY26 came in at 75.0% GAAP; Q1 FY26 printed 60.5% only because of a one-time $4.5B inventory charge tied to H20 China export restrictions (~71.3% normalized). When the supplier of a critical input runs that kind of margin, the buyer is paying roughly 4× the manufactured silicon cost. At ~$700B aggregate capex, even pulling 20% of that spend in-house claws back $35B+ a year for the cohort. That math is the entire reason every hyperscaler now has a chip team.
Workload specificity. Transformer training and inference at hyperscale have stable shapes. They do not need NVIDIA general-purpose flexibility — they need raw throughput on a known kernel. Custom ASICs (TPU, Trainium, MTIA, MAIA) trade flexibility for efficiency and beat NVIDIA on specific workloads when the silicon is matched tightly to the model.
Roadmap control. NVIDIA ships a major architecture every two years (Hopper, Blackwell, Rubin). Hyperscalers ship new models every month. Owning the silicon means owning the cadence — you do not wait on someone else road map when the product you are building is moving faster than their fab cycle.
Supply security. The 2022–2024 NVIDIA allocation wars were a structural lesson: buying 100% of a critical input from one supplier is an existential risk. Hyperscaler boards now treat single-vendor concentration as a governance issue, not just a procurement preference.
Where each hyperscaler actually is
Four years ago this was a Google story with a Wall Street footnote. Today it is five concurrent programs at five different maturity stages.
| Hyperscaler | Chip family | Current generation & status | Design partner | Primary workload |
|---|---|---|---|---|
| TPU | v6 Trillium (shipping; ~1.6M units expected in 2026); v7 Ironwood (GA late 2025; Anthropic committed up to 1M chips) | Broadcom (AVGO) — long-term agreement through 2031 | Training + inference, frontier + serving | |
| Amazon | Trainium / Inferentia | Trainium2 (Project Rainier supercluster ~500K+ chips active); Trainium3 (shipping early 2026; UltraServers GA Dec 2025) | Marvell (MRVL) + in-house Annapurna Labs | Anthropic training + general AWS inference |
| Meta | MTIA | v2 deployed at scale for ranking/ads; MTIA 400 series rollout under the April 14, 2026 Broadcom extension (multi-GW roadmap, 6-month dev cadence) | Broadcom (AVGO) + in-house | Ranking, ads, Llama training (v3+) |
| Microsoft | MAIA / Cobalt | MAIA 100 deployed in Azure; MAIA 200 slipped to 2026 mass production per mid-2025 reporting | In-house + GUC | Azure AI inference + internal Copilot |
| Apple | M-series + server silicon | M4 in consumer; bespoke server silicon for Apple Intelligence private cloud | In-house | On-device + Apple Intelligence |
Google TPU is the only one of these that has shipped at scale for a decade — seven generations, the most mature stack, and a long-term design partnership with Broadcom that now extends through 2031. Amazon is in active rollout: Trainium2 is fully subscribed and a multi-billion-dollar business, Trainium3 began shipping early 2026, and Anthropic — Amazon flagship AI tenant — committed more than $100B in AWS spend over 10 years and signed for 5GW of new capacity. Meta MTIA is deployed at scale for the part of the business that funds everything else (ranking and ads on Instagram and Facebook); the April 14, 2026 multi-gigawatt partnership extension with Broadcom moves MTIA up the workload stack toward Llama training. Microsoft is the most cautious of the four — MAIA 100 is in production for internal workloads, but the company is still NVIDIA-heavy and MAIA 200 has slipped.
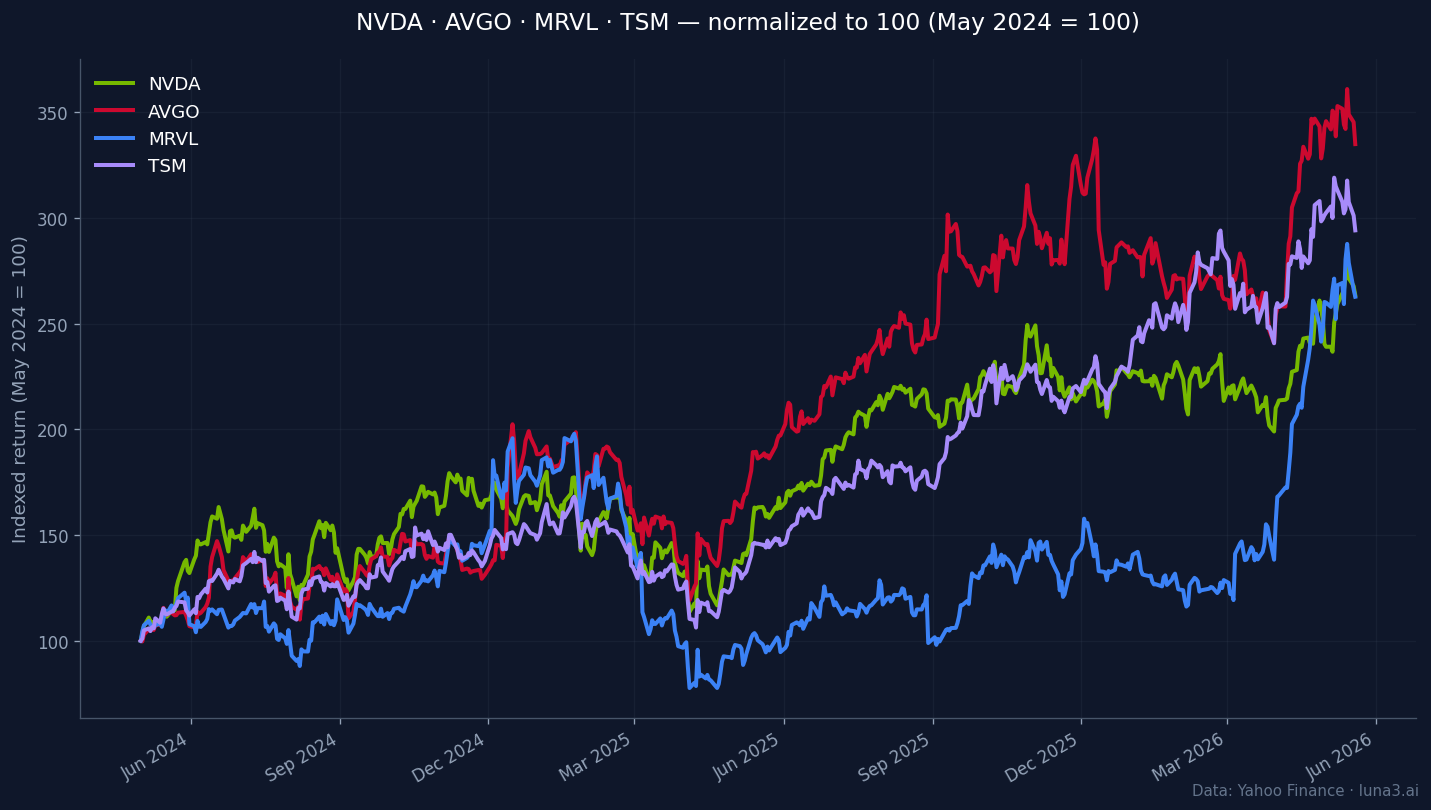
Where the money flows
This is where most coverage of the custom silicon race stops short. The interesting investor question is not “does NVIDIA win or lose?” It is “who is paid in every scenario?” Five buckets, in order of leverage:
NVIDIA (NVDA). Still wins the majority of training compute. CUDA remains the default software stack for any new model that has not been deliberately ported to TPU or Trainium kernels. NVIDIA HBM access (covered in our earlier piece on HBM memory as the bottleneck behind every AI chip) and general-purpose flexibility keep it dominant in frontier research and any workload that has not stabilised. Steady-state share probably settles around 50–60% of hyperscaler AI silicon spend by 2028 — down from today but still the single largest line item.
Broadcom (AVGO). The most under-appreciated winner in the cohort, and the one to study most carefully. Broadcom is the custom silicon design partner for Google TPU (more than a decade, seven generations, the agreement just extended through 2031) and Meta MTIA (the April 2026 extension covers MTIA 400 with a six-month development cadence). AVGO AI revenue trajectory speaks for itself: $12.2B in FY24 at +220% year-over-year; Q1 FY26 alone printed $8.4B (+106% YoY); company guidance for Q2 FY26 sits at $10.7B. Broadcom now claims roughly 75% of the custom ASIC market, and Counterpoint Research forecasts ~60% sustained share by 2027 even as more competitors enter.
Marvell (MRVL). The AVGO comparison case. Smaller scale, but the primary design partner for Amazon Trainium2 and Inferentia 2.5 under a five-year agreement signed late 2024. The optical and interconnect business adds optionality on top of the ASIC story. MRVL trades at a meaningful discount to AVGO on AI revenue mix, which is part of the trade-off — Broadcom has the dominant share, Marvell has the higher beta to a single hyperscaler getting it right.
TSMC (TSM). Every chip mentioned in this piece — Trillium, Ironwood, Trainium2, Trainium3, MTIA v2, MAIA 100, NVIDIA Blackwell and Rubin — gets fabbed at TSMC. The advanced node + advanced packaging combination at hyperscaler volume is something no other foundry can match (the second-order bottleneck is CoWoS capacity, which we covered in the CoWoS packaging shortage). TSMC has pricing power across every outcome of the NVIDIA-vs-ASIC question.
Synopsys (SNPS) and Cadence (CDNS). The EDA toolchain underneath every custom design. Synopsys, Cadence and Siemens EDA dominate the high-end electronic design automation market between them, and both Synopsys and Cadence are growing at 15–20% CAGR on the back of the hyperscaler in-house silicon trend. They get paid whether the chip ships well or not — the licence and tool revenue lands during design, before any silicon enters the foundry.
Two layers below the surface, the memory cohort (Micron, SK Hynix, Samsung) is the bottleneck supply chain that constrains every chip in this race regardless of who designs it. And the hyperscalers themselves capture the value that migrates out of NVIDIA gross margin — the 20-percentage-point gap between NVIDIA 75% gross margin and AWS/Azure/GCP cloud operating margins is exactly what custom silicon is built to recapture.
What this means for NVIDIA — the steady-state math
NVIDIA Q1 FY26 8-K filing disclosed that roughly 53% of data center revenue came from three unnamed customers — about $21.9B in the quarter, with Customer A alone representing more than 20% of total NVIDIA revenue. Taken across the Big 4 hyperscalers in aggregate, the concentration is materially higher than that. This is the data point that frames the rest of the analysis.
Three scenarios resolve from here:
Bear case. ASIC displacement caps NVIDIA at general training and frontier research. Inference and recommender workloads — where the unit economics matter most — migrate to in-house silicon. NVIDIA top line still grows in absolute dollars, but the customer mix diversifies, hyperscaler share of NVIDIA revenue declines, and the forward multiple compresses from today ~30× toward 20×.
Bull case. AI workload demand grows faster than hyperscaler ASIC capacity can scale. NVIDIA + ASIC is additive, not substitutive. CUDA keeps NVIDIA the default for everything new, and the ASIC programs absorb the well-understood tail of inference workloads while NVIDIA owns the frontier. The strongest piece of evidence for this case is Anthropic: the largest AI customer in the world is simultaneously committed to up to 1 million Google Ironwood TPUs and to $100B+ in AWS Trainium spend over a decade. The only way that allocation makes sense is if total demand exceeds what any single vendor — NVIDIA, Google, or Amazon — can deliver.
Middle case (the most likely). NVIDIA grows in absolute dollars; the customer mix diversifies meaningfully through 2027–2028 as Trainium3 ramps and MTIA moves up the workload stack; hyperscaler ASIC takes share at the margins of inference; and the NVIDIA multiple normalises from current ~30× forward earnings toward ~22–25×. Not a disaster for NVDA. But not the path that historically delivered the AVGO-style return.
What could invalidate the picks-and-shovels read
Every thesis deserves a clean counter-argument. Four things would break the ASIC-stack call:
NVIDIA closes the efficiency gap. The Rubin architecture (and the Vera/Vera Rubin generations after) is being explicitly engineered to compete with custom ASICs on perf-per-watt and perf-per-dollar at workload-specific shapes. If NVIDIA delivers on Rubin targets and prices aggressively, hyperscaler ASIC roadmaps slow and the design-partner spend (AVGO, MRVL) compresses with them.
Open-source ASIC designs go mainstream. Tenstorrent RISC-V-based architecture, Cerebras wafer-scale system, and a handful of well-capitalised privates could reach hyperscaler-grade reliability over the next 24–36 months. If they do, the proprietary design-partner moat that AVGO and MRVL currently price on starts to look thinner.
The inference TAM does not materialise. Most of the capex math assumes inference demand grows roughly linearly with model deployment. If usage stalls at the application layer — chatbots and Copilots that do not graduate into agents that consume orders of magnitude more compute — the whole capex cycle re-rates lower. Every player in this piece is exposed.
Geopolitics fractures the supply chain. Tighter export controls on advanced GPUs, HBM, and EUV lithography push China onto a parallel stack (Huawei Ascend, SMIC, domestic HBM). Bifurcation reduces the global TAM that today multiples implicitly assume.
What we are watching over the next 12 months
Five signals deserve attention if you are tracking the custom silicon race from here:
- Q2/Q3 2026 hyperscaler capex updates. MSFT, GOOGL, META and AMZN earnings — does aggregate run rate hold ~$700B, accelerate further, or show the first signs of moderation?
- Production cadence on the in-house chips. Trainium3 ramp through 2026, MTIA 400 series rollout under the new Broadcom cadence, Ironwood volume numbers, and any update on MAIA 200 timing.
- NVIDIA Rubin Ultra launch and pricing. The Rubin generation is the test of whether NVIDIA can close the efficiency gap before custom silicon takes meaningful share.
- AVGO AI revenue mix. Q3 and Q4 FY26 — does the trajectory from $8.4B (Q1) to $10.7B (Q2 guide) continue toward a $50B+ annual AI run-rate?
- Anthropic deployment mix. What fraction of Anthropic actual compute lands on Trainium vs Ironwood vs NVIDIA? The first hard data on whether the multi-vendor commitment is real allocation or PR allocation will tell you a lot about whether the additive-market thesis holds.
The custom silicon race is, on the surface, a story about whether NVIDIA loses market share. One layer below the surface, it is a story about the largest concurrent in-house chip program in computing history reshaping the entire semiconductor supply chain. The investor edge is rarely in the headline fight. It is in the suppliers that get paid regardless of who wins it — and right now those are Broadcom, Marvell, TSMC, Synopsys and Cadence, sitting one rung above the ASIC battle and collecting toll on every chip that ships.
Get early access to Orbit
Orbit is Luna3.ai’s AI-augmented research engine. 12 algorithmic signals + a gradient-boosted ML model + an agentic LLM that reads each top pick’s filings and writes a daily thesis with conviction score and catalyst proximity. Three regimes, three playbooks — growth in expansion, defensives in late-cycle, recovery plays at panic bottoms. The 3 in Luna3.ai.
No spam. Unsubscribe any time.
No comments yet. Be the first to share your thoughts!